AI for Speech Therapy and Language Acquisition
Learning a new language involves constantly comparing speech productions with reference productions from the environment. Early in speech acquisition, children make articulatory adjustments to match the speech of their caregivers. Grown-up learners of a language tweak their speech to match the tutor’s reference. This process—often subconscious—is rooted in our capacity for auditory discrimination and motor imitation. Children rely heavily on auditory feedback and social interaction to fine-tune their articulations, gradually developing more accurate phonological patterns. Adults, while often more constrained by established motor habits and native-language interference, engage in similar feedback loops, leveraging mimicry, corrective feedback, and phonetic training to reshape their speech output. In both cases, the interplay between perception and production underpins the journey from misarticulated attempts to intelligible speech, highlighting the brain’s remarkable adaptability across the lifespan.
Can we design a system that delivers precise auditory and visual feedback to language learners—and especially to individuals with Speech Sound Disorders (SSD) who require speech therapy? Just as typical language learners refine their speech by comparing their own productions to native reference examples, individuals with SSD benefit greatly from clear and immediate corrective feedback that helps them form accurate sound patterns. In both groups, progress hinges on the ability to perceive and respond to differences between their own speech and the target pronunciation.
Children and adults with SSD often struggle with consistently producing certain sounds correctly. Speech therapy addresses this by focusing on developing the necessary motor skills through targeted feedback, emphasizing how a sound should be formed and perceived. Among various therapeutic strategies, the quality and immediacy of feedback is arguably the most vital component—it helps learners construct a reliable internal model of correct pronunciation.
To enhance this process, we propose an intelligent algorithm that generates synthetic, corrective feedback in the learner’s own voice. For instance, imagine a learner named Ron who has difficulty articulating the /r/ sound in American English. Whether this is due to a speech disorder or because English is his second language, the system can help. If Ron attempts to say “right” but produces “white” instead—substituting /w/ for /r/—the system will respond: “Ron, you said white, but you should have said right,” where right is rendered synthetically in Ron’s own voice. This personalized correction makes it easier for Ron to perceive the difference and attempt a more accurate repetition.
At the core of this approach is a pronunciation transformation algorithm: it takes the mispronounced audio as input and generates a corrected version that preserves the speaker’s unique vocal characteristics. Research suggests that maintaining the original voice in feedback—rather than using a generic synthesized speaker—enhances the learner’s engagement and self-awareness (Strömbergsson et al., 2014). By aligning the correction with the learner’s identity, we aim to make feedback more intuitive, motivating, and effective.
How does it work?
The mobile app prompts the user to pronounce a specific word or phrase. In this instance, it is requesting the user to say: “Very short.”

The mobile app prompts the user to pronounce a specific word or phrase. In this instance, it is requesting the user to say: “Very short.”
The user mispronounced the target phrase by substituting the /ʃ/ (“sh”) sound with /s/, resulting in “Very sort” instead of “Very short.”
The recorded speech is first converted into a spectrogram. Next, a phoneme-to-speech alignment process—known as forced alignment—is performed. This step maps each phoneme in the expected phrase to its corresponding time interval in the user’s audio, allowing precise identification of where and how the mispronunciation occurred.

Speech to phoneme alignment.
Once the phoneme-to-speech alignment is complete, the system identifies the misproduced phoneme—in this case, /s/ in place of the expected /ʃ/. The mispronounced segment, along with a small surrounding region to ensure smooth audio transitions, is then extracted and removed from the spectrogram.

The mispronounced segment, along with a small surrounding region to ensure smooth audio transitions, is then extracted and removed from the spectrogram.
A new speech spectrogram is then generated to fill in the missing segment where the mispronounced phoneme was removed. This process is handled by a deep neural network trained specifically for speech synthesis. The model functions analogously to image inpainting—it reconstructs the missing portion of the spectrogram based on the surrounding acoustic context, ensuring coherence in both content and speaker identity. The result is a corrected version of the original phrase, with the appropriate phoneme seamlessly integrated into the user’s own voice.
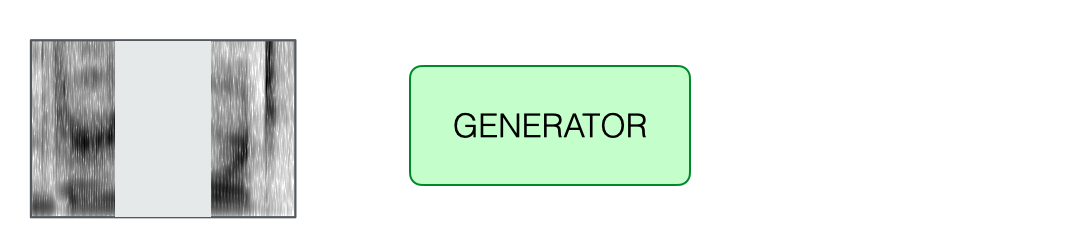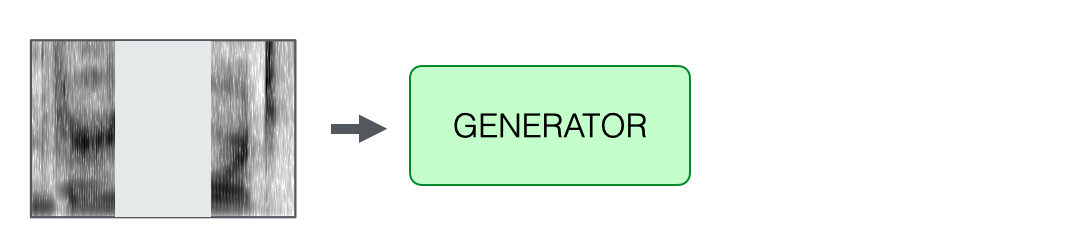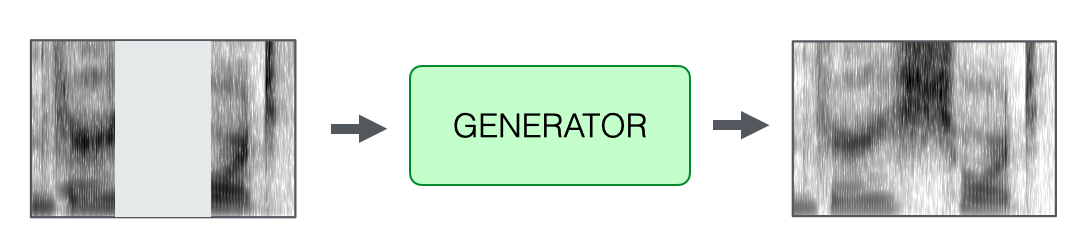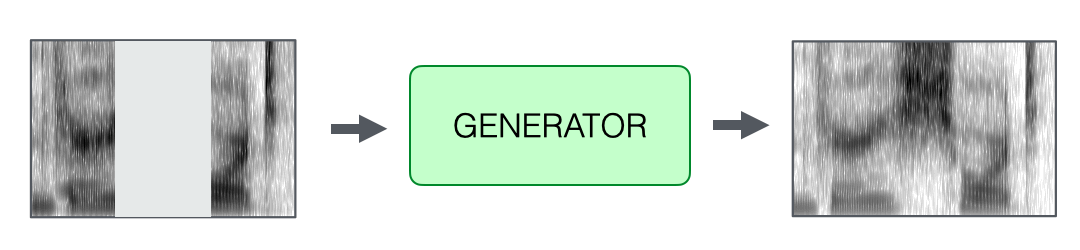
Inpainting of the removed segment.
The newly generated spectrogram is converted to a waveform using the HiFi-GAN vocoder. It is played back to the user.

The newly generated spectrogram is played back to the user.
Why Is This Exciting?
For the first time, we can take a mispronounced utterance and automatically correct it—in the speaker’s own voice. This marks a significant breakthrough in speech technology. What makes the approach even more compelling is that the algorithm does not require parallel training data. That is, it doesn’t need to be trained on pairs of correct and incorrect pronunciations from the same speaker. Instead, it learns solely from correctly pronounced speech by others, making it highly scalable and adaptable.
Additionally, the system doesn’t need to be personalized or retrained for each new user. It generalizes from “healthy” speech patterns and can be applied immediately to new speakers without any fine-tuning. This makes it practical for wide deployment, even in resource-limited settings.
The implications are profound. By integrating AI-driven feedback into language learning and speech therapy, we can significantly boost both the effectiveness and engagement of the learning process. More importantly, this technology holds the potential to transform speech therapy access—especially for individuals with Speech Sound Disorders in rural or underserved regions, including many communities across Africa. It opens a path to high-quality, scalable, and personalized speech support where it’s most needed.
References
Strömbergsson, S., Wengelin, Å., & House, D. (2014). Children’s perception of their synthetically corrected speech production. Clinical linguistics & phonetics, 28(6), 373-395.
Talia ben Simon, Felix Kreuk, Faten Awwad, Jacob T. Cohen, Joseph Keshet, (2022). Correcting Misproducted Speech using Spectrogram Inpainting, The 23rd Annual Conference of the International Speech Communication Association (Interspeech), Incheon, Korea.